
Feature Engineering
As the basic exploratory data analysis (EDA), we need to identify some features that allow us to distinguish spam emails from ham emails. One idea is to compare the distribution of a single feature in spam emails to the distribution of the same feature in ham emails. If the feature is itself a binary indicator, such as whether a certain word occurs in the text, this amounts to comparing the proportion of spam emails with the word to the proportion of ham emails with the word. Some words that were chosen to demonstrate this were plotted below, and significant differences are observed.
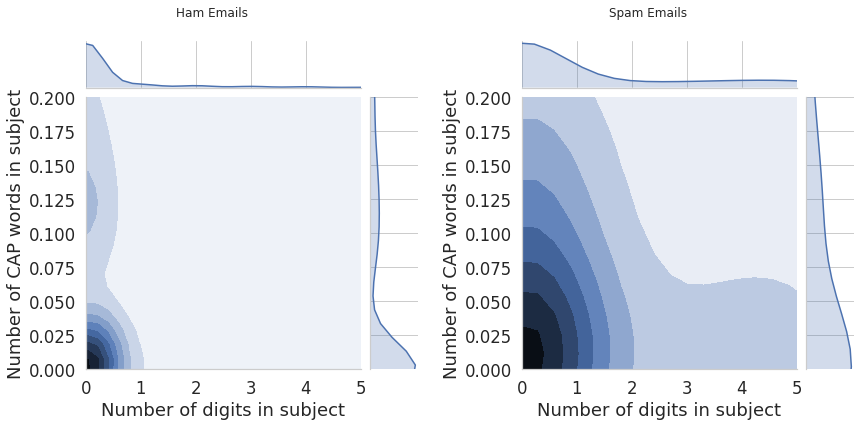
Two joint plots are shown below to show the difference between spam emails and ham emails in terms of their subject. I explored this from two aspects. One is the number of digits in the subject, and the other is the number of all cap words in the subject. We can see that the distributions are drastically different where as spam emails tend to have a lot of both all caps and digits ham emails tend to have none of those.
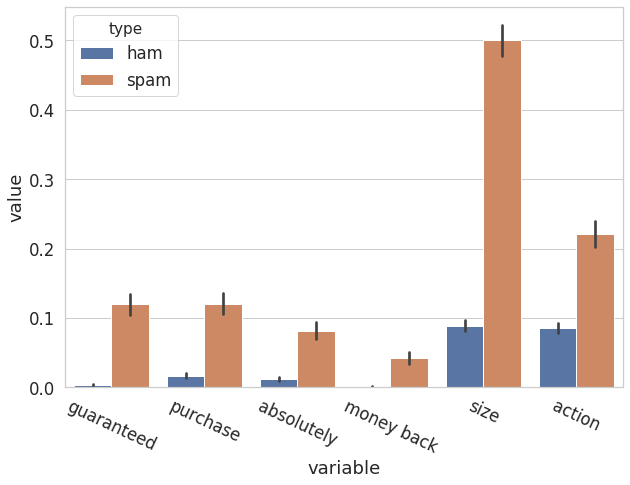
I looked at the subjects and email bodies of the spam emails, and tried to find something that is unique about them, and I also did the same to ham emails. Then I tried to test these features by simply visualize them on the bar plot to see the proportions in spam and ham emails. Finally, I collected all the word characters and sorted them by reduced difference and chose the largest ones to be in the keywords while using cross-validation to find the right number of features to use for both subject and email. I tried length of subject, number of HTML and their elements like tables, but none of them seemed to have too much power distinguishing between spam and ham emails. Some keywords like Re:, [ however, contributed quite some power in terms of distinguishing the emails. Surprisingly, some features that I thought would make a difference on my training accuracy, turned out not making a big difference, like forwarded emails, https:, etc.
As a result, the following features are considered:
1. Keywords in email body
2. Keywords in email subject
3. Percentage of all caps words in the subject
4. Number of digits in subject
5. Number of links(href) in email
Classifications
Using the features selected above, I was able to train my final model for submission to Kaggle to get get scored on the test data sets. Before my submission, I plotted an ROC curve for my final model on the validation data sets to show the trade off for each possible cutoff probability.
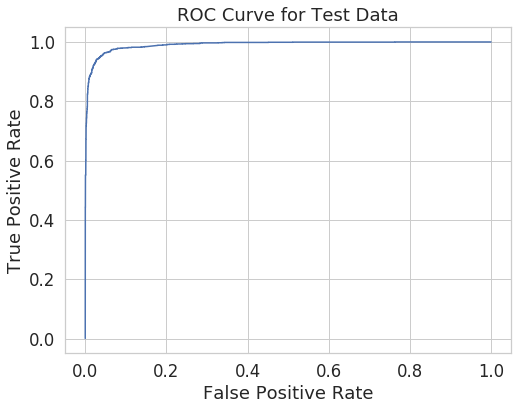
Final Kaggle public score: 0.9500